이모티콘 플러스 가입자를 최대한으로 늘리면서, 이모티콘 플러스 가입자 수가 최대인 상태에서 판매액 또한 최대로 높일 수 있는 경우를 탐색하여 그 경우의 이모티콘 플러스 가입자 수와 이모티콘 판매액을 반환하는 문제이다.
모든 유저는 2가지의 기준을 따라 소비를 한다.
1.본인이 설정한 최소 할인율을 기준으로 동일하거나 더 많이 할인하는 이모티콘은 모두 구매한다.
A유저가 설정한 최소 할인율이 20%라고 가정해보자. 만약, 4개의 이모티콘이 각각 10%, 30%, 20%, 40%를 할인한다면 A유저는 2번,3번,4번 이모티콘을 구매할 것이다. 1번 이모티콘은 최소 할인율보다 적게 할인하기 때문에 구매하지 않는다.
2. 이모티콘 구매액이 일정 금액을 넘어가면, 이모티콘을 구매하지 않고 이모티콘 플러스에 가입한다.
A유저가 설정한 최대 구매 금액이 10000원이라고 해보자. 1번 기준에 의해 구매하기로 한 이모티콘의 가격에 할인까지 적용된 최종 가격이 10000원 이상이라면 이모티콘을 구매하지 않고 이모티콘 플러스에 가입할 것이다.
이 경우에 카카오톡 입장에선, 이모티콘 플러스의 가입자는 1명 증가하고 이모티콘 판매액은 0원이 증가하는 셈이 된다.
이모티콘의 할인율을 어떻게 세팅해야 카카오톡이 원하는 최적의 결과가 나올 수 있는지 구한 뒤, 해당 경우에 카카오톡 플러스의 가입자 수와 총 판매액을 구하면 된다.
문제 풀이
본인은 해당 문제를 DFS를 사용한 완전탐색으로 해결하였다.
문제의 조건 이모티콘의 최대 갯수는 7개로 주어진다.
이모티콘에 적용할 수 있는 할인율은 10%, 20%, 30%, 40%로 총 4개이므로 이모티콘에 할인을 적용하는 모든 경우의 수는 4^7 (16384)가 된다.
이정도 개수면 완전탐색하기에 충분하고도 남는다.
먼저, DFS를 사용하여 모든 경우의 수를 탐색하였다.
그리고, DFS가 끝에 도달했을 때 선택된 할인율을 기준으로 유저들의 반응을 조사한 뒤, 나온 결과물을 pair (가입자 수, 총 판매액)에 저장한 뒤, 해당 pair를 set에 삽입하였다.
pair은 기본적으로 first를 기준으로 대소를 비교한 뒤, first가 같다면 second를 기준으로 대소를 비교하게 된다.
즉, 카카오톡 플러스 구독자 수를 기준으로 정렬을 한 뒤, 구독자 수가 같다면 총 매출액으로 정렬하는 것이다.
그러므로, 오름차순으로 정렬된 set의 가장 마지막 원소가 우리가 원하는 답이 되는 것이다.
풀이 코드
struct UserInfo
{
int MinSale = 0;
int MaxPrice = 0;
};
std::vector<UserInfo> Users;
std::vector<int> EmoPrices;
std::vector<std::vector<bool>> isVisit;
std::set<std::pair<int, int>> Answers;
먼저 1개의 구조체와 4개의 자료구조를 선언하였다.
UserInfo는 입력으로 들어온 User의 정보를 좀 더 효율적으로 사용하기 위해 만들었다.
UserInfo에 데이터를 저장한 뒤 Users에 삽입해주었다.
EmoPrice또한, 입력으로 들어온 이모티콘의 가격들을 그대로 복사해준 것이다.
전역변수로 선언하여 다른 함수에서 쉽게 참조할 수 있도록 하기 위함이다.
isVisit는 DFS를 사용하기 위한 방문체크 배열이다.
Answer은 모든 경우의 수를 담게 될 자료구조이다.
Users.resize(users.size());
EmoPrices.resize(emoticons.size());
isVisit.resize(emoticons.size(), std::vector<bool>(4, false));
for(int i = 0; i < users.size(); i++)
{
UserInfo NewUser;
NewUser.MinSale = users[i][0];
NewUser.MaxPrice = users[i][1];
Users[i] = NewUser;
}
for(int i = 0; i < emoticons.size(); i++)
{
EmoPrices[i] = emoticons[i];
}
먼저 이렇게, 입력을 저장해주었다.
isVisit의 내부 배열을 보면 4로 resize해주고 있는데, 할인 경우의 수가 4가지이기 때문이다.(10%, 20%, 30%, 40%)
for(int i = 0; i < 4; i++)
{
DFS(0, i);
}
std::set<std::pair<int, int>>::iterator Iter = Answers.end();
Iter--;
return {Iter->first, Iter->second};
그 다음은 위에서 말한 것과 같이 DFS를 사용하여 완전탐색을 하였다.
Answer의 마지막 원소의 값을 답으로 반환해주고 있다.
void DFS(int _CurEmoIndex, int _CurSaleIndex)
{
if(_CurEmoIndex == EmoPrices.size())
{
int SubScriber = 0;
int Revenue = 0;
for(int i = 0; i < Users.size(); i++)
{
int Result = GetRevenue(i);
if(Result == -1)
{
SubScriber++;
}
else
{
Revenue += Result;
}
}
Answers.insert({SubScriber, Revenue});
return;
}
isVisit[_CurEmoIndex][_CurSaleIndex] = true;
for(int i = 0; i < 4; i++)
{
DFS(_CurEmoIndex + 1, i);
}
isVisit[_CurEmoIndex][_CurSaleIndex] = false;
}
이는 DFS함수 내부이다.
인자로는 현재 이모티콘의 인덱스와 할인율(0->10%, 1->20%, 2->30%, 3->40%)을 받고 있다.
가장 위의 조건문을 보자.
DFS가 모든 이모티콘을 탐색하였다면, 현재 선택된 이모티콘과 할인율에 대해 유저의 반응을 계산해주고 있다.
GetRevenue는 특정 유저가 이모티콘에 얼마를 지불하는가를 구하는 함수이다. 내부 코드는 잠시 뒤에 보도록 하자.
GetRevenue는 유저가 이모티콘을 구매하지 않고 이모티콘 플러스에 가입한다면, -1을 반환하도록 설정하였다.
이 값을 기반으로 SubScriber와 Revenue를 모든 유저에 대해 갱신해주었고, 해당 값을 Answer에 삽입해주었다.
탈출 분기 뒤엔 DFS코드가 작성되어 있다.
먼저, isVisit를 true로 만들어준 뒤, DFS가 끝나면 isVisit를 false로 만들어주었다.
isVisit를 false로 만드는 코드가 없다면 n개의 원소에 대해 DFS는 정확히 n번의 탐색을 한다.
하지만, isVisit를 false로 만드는 코드를 넣는다면, 가능한 모든 경우의 수를 탐색하게 된다.
int GetRevenue(int _UserIndex)
{
int Cost = 0;
for(int i = 0; i < isVisit.size(); i++)
{
for(int j = 0; j < isVisit[i].size(); j++)
{
if(isVisit[i][j] == false)
{
continue;
}
int Sale = (j + 1) * 10;
if(Sale >= Users[_UserIndex].MinSale)
{
int CurEmoPrice = EmoPrices[i];
CurEmoPrice *= (1.0f - (float)Sale / 100.0f);
Cost += CurEmoPrice;
break;
}
}
}
if(Cost >= Users[_UserIndex].MaxPrice)
{
//Cost가 -1이면, 이모티콘 플러스 가입.
Cost = -1;
}
return Cost;
}
GetRevenue함수의 코드이다.
isVisit의 값을 기준으로 각 이모티콘에 적용된 할인율을 탐색하고 있다.
해당 할인율을 기준으로, 구매할 이모티콘의 총 금액을 계산한 뒤 유저의 기준 금액과 비교하여 구매할 지, 이모티콘 플러스에 가입할 지를 계산하였다.
만약, 이모티콘 플러스에 가입한다면 반환값을 -1로 바꿔서 반환해주었다.
이렇게 DFS를 사용하여 모든 경우의 수에 대해 유저들의 반응을 탐색한 뒤 나온 결과 중 최고의 결과를 출력해주면 되는 문제였다.
코드 전문
#include <string>
#include <vector>
#include <set>
#include <iostream>
using namespace std;
struct UserInfo
{
int MinSale = 0;
int MaxPrice = 0;
};
std::vector<UserInfo> Users;
std::vector<int> EmoPrices;
std::vector<std::vector<bool>> isVisit;
std::set<std::pair<int, int>> Answers;
int GetRevenue(int _UserIndex)
{
int Cost = 0;
for(int i = 0; i < isVisit.size(); i++)
{
for(int j = 0; j < isVisit[i].size(); j++)
{
if(isVisit[i][j] == false)
{
continue;
}
int Sale = (j + 1) * 10;
if(Sale >= Users[_UserIndex].MinSale)
{
int CurEmoPrice = EmoPrices[i];
CurEmoPrice *= (1.0f - (float)Sale / 100.0f);
Cost += CurEmoPrice;
break;
}
}
}
if(Cost >= Users[_UserIndex].MaxPrice)
{
//Cost가 -1이면, 이모티콘 플러스 가입.
Cost = -1;
}
return Cost;
}
void DFS(int _CurEmoIndex, int _CurSaleIndex)
{
if(_CurEmoIndex == EmoPrices.size())
{
int SubScriber = 0;
int Revenue = 0;
for(int i = 0; i < Users.size(); i++)
{
int Result = GetRevenue(i);
if(Result == -1)
{
SubScriber++;
}
else
{
Revenue += Result;
}
}
Answers.insert({SubScriber, Revenue});
return;
}
isVisit[_CurEmoIndex][_CurSaleIndex] = true;
for(int i = 0; i < 4; i++)
{
DFS(_CurEmoIndex + 1, i);
}
isVisit[_CurEmoIndex][_CurSaleIndex] = false;
}
vector<int> solution(vector<vector<int>> users, vector<int> emoticons)
{
Users.resize(users.size());
EmoPrices.resize(emoticons.size());
isVisit.resize(emoticons.size(), std::vector<bool>(4, false));
for(int i = 0; i < users.size(); i++)
{
UserInfo NewUser;
NewUser.MinSale = users[i][0];
NewUser.MaxPrice = users[i][1];
Users[i] = NewUser;
}
for(int i = 0; i < emoticons.size(); i++)
{
EmoPrices[i] = emoticons[i];
}
for(int i = 0; i < 4; i++)
{
DFS(0, i);
}
std::set<std::pair<int, int>>::iterator Iter = Answers.end();
Iter--;
return {Iter->first, Iter->second};
}'코딩테스트 문제 풀이 (C++)' 카테고리의 다른 글
| 프로그래머스 - N진수 게임 (C++) (0) | 2024.05.10 |
|---|---|
| 프로그래머스 - 이중 우선순위 큐 (C++) (0) | 2024.05.10 |
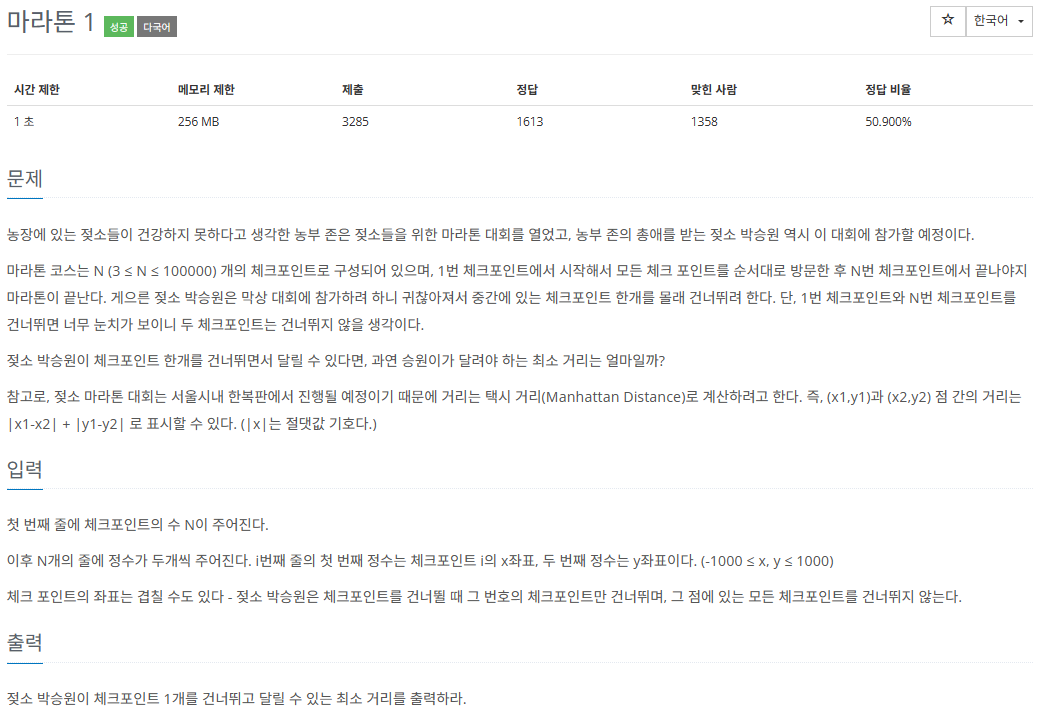
| 백준 10655 - 마라톤 (C++) (0) | 2024.05.07 |
| 백준 1935 - 후위 표기식 (C++) (0) | 2024.05.06 |
| 백준 16120 - PPAP (C++) (0) | 2024.05.04 |