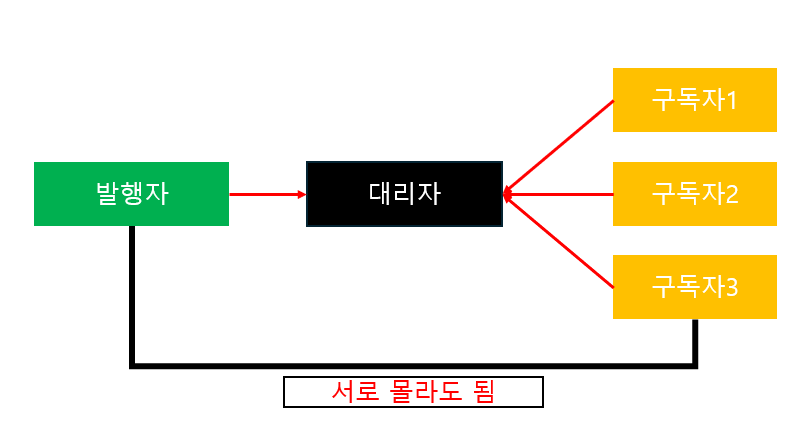
A = 1, B = 2, C = 3 ... Z = 26 등 알파벳을 각 순서와 동일한 숫자로 치환하여 새로운 숫자 문자열을 만든다.
해당 숫자 문자열을 다시 기존의 알파벳 문자열로 복호화하게 되면, 경우의 수가 하나가 아니라 여럿 존재할 수 있다.
예를 들어, 19의 경우 1 + 9 => AI 로 표현할 수도 있지만, 19 -> S 로 표현할 수도 있다.
이처럼, 숫자 문자열이 주어졌을 때 해석 가능한 알파벳 문자열의 경우의 수를 출력하면 된다.
주의할 점은 경우의 수가 매우 많으므로 1000000으로 나눠서 저장하도록 하자.
문제 풀이
DP를 이용하여 풀 수 있는 문제이다.
입력된 문자열을 순차적으로 탐색하며, 현재 가리키는 숫자가 1자리 숫자로 해석될 수 있는 경우와 2자리 숫자의 1의 자리로 해석될 수 있는 경우를 구해주면 된다.

이렇게 길이가 5인 문자열 "12345"가 주어졌다고 해보자.
"12345"의 부분 문자열인 "123"에 대해 경우를 생각해보자.

123은 위와 같이 3개의 경우를 가지며, 3개의 경우는 2개의 종류로 나누어 볼 수 있다.
1. 마지막 숫자가 한 자리수인 경우
2. 마지막 숫자가 두 자리수의 1의 자리인 경우
1번 경우를 살펴보자.
1번 경우는 마지막 3을 제외한 앞의 숫자들을 보면 규칙이 보인다.
12를 해석하는 경우의 수이다.
즉, 길이가 N인 문자열을 해석할 때, 마지막 숫자를 한자리 숫자라고 고려한다면
0 ~ (N - 1) 의 문자열을 해석하는 경우의 수와 동일하다는 것이다
2번 경우도 살펴보자.
2번 경우는 마지막 숫자가 두 자리수의 1의 자리라고 했기 때문에, 그 앞의 숫자는 두자리 숫자의 10의 자리가 된다.
1번 경우를 살필 때와 동일하지만, 이 번엔 두자리 숫자이므로 0 ~ (N - 2) 길이의 문자열을 해석하는 경우의 수와 동일하게 된다.
즉 DP(N)을 길이가 N인 문자열을 해석하는 경우의 수라고 한다면, DP(N) = DP(N - 1) + DP(N - 2)가 된다.
풀이 코드
std::string Encryption;
std::cin >> Encryption;
if (Encryption[0] == '0')
{
std::cout << 0;
return 0;
}
if (Encryption.size() == 1)
{
std::cout << 1;
return 0;
}먼저 입력을 받아주었다.
이후, 맨 앞이 0으로 시작하거나 길이가 1인 경우에 대해 예외처리를 해주었다.
std::vector<int> DP(Encryption.size());
DP[0] = 1;
int FrontTwoNum = std::stoi(Encryption.substr(0, 2));
if (FrontTwoNum >= 10 && FrontTwoNum <= 26)
{
DP[1] += 1;
}
if(Encryption[1] - '0' != 0)
{
DP[1] += 1;
}다음은 DP배열을 선언해주었다.
DP[0]은 한자리 숫자로 해석되는 1가지 경우밖에 없기 때문에 1로 초기화할 수 있다.
DP[1]의 경우 두 가지를 고려할 수 있다.
12처럼 1 + 2, 12 이렇게 두가지로 해석되는 경우가 있고
27처럼 2 + 7로만 해석되는 경우가 있다.
그러므로, 앞자리 숫자와 현재숫자를 고려하여 두가지 경우로 해석될 수 있는 경우엔 DP[1] = 2 로 초기화하였고, 아닌 경우엔 1로 초기화하였다.
for (int i = 2; i < Encryption.size(); i++)
{
int CurNum = Encryption[i] - '0';
int PrevNum = Encryption[i - 1] - '0';
if ((PrevNum == 1 && CurNum <= 9) || (PrevNum == 2 && CurNum <=6))
{
DP[i] += DP[i - 2];
}
if (CurNum != 0)
{
DP[i] += DP[i - 1];
}
DP[i] %= 1000000;
}그 다음은 반복문을 돌며 DP배열을 갱신해주었다.
만약, 현재 숫자와 앞의 숫자를 합한 두자리 숫자가 10~26 사이의 숫자로 해석될 수 있다면 DP[i -2]를 DP[i]에 더해주었으며, 1~9로 해석될 수 있는 경우에는 DP[i]를 더해주었다.
만약, 현재 숫자가 0이라면 한자리 숫자로는 해석될 수 없다.
경우의 수가 커지는 것을 방지하여 문제의 조건에 맞게 1000000으로 나누어서 저장해주자.
std::cout << DP[DP.size() - 1];
return 0;
DP의 마지막 원소를 출력해주면 문제 해결이다.

코드 전문
#include <iostream>
#include <vector>
#include <string>
void Init()
{
std::ios::sync_with_stdio(false);
std::cin.tie(nullptr);
std::cout.tie(nullptr);
}
int main()
{
Init();
std::string Encryption;
std::cin >> Encryption;
if (Encryption[0] == '0')
{
std::cout << 0;
return 0;
}
if (Encryption.size() == 1)
{
std::cout << 1;
return 0;
}
std::vector<int> DP(Encryption.size());
DP[0] = 1;
int FrontTwoNum = std::stoi(Encryption.substr(0, 2));
if (FrontTwoNum >= 10 && FrontTwoNum <= 26)
{
DP[1] += 1;
}
if(Encryption[1] - '0' != 0)
{
DP[1] += 1;
}
for (int i = 2; i < Encryption.size(); i++)
{
int CurNum = Encryption[i] - '0';
int PrevNum = Encryption[i - 1] - '0';
if ((PrevNum == 1 && CurNum <= 9) || (PrevNum == 2 && CurNum <=6))
{
DP[i] += DP[i - 2];
}
if (CurNum != 0)
{
DP[i] += DP[i - 1];
}
DP[i] %= 1000000;
}
std::cout << DP[DP.size() - 1];
return 0;
}'코딩테스트 문제 풀이 (C++)' 카테고리의 다른 글
| 백준 1106 - 호텔 (C++) (0) | 2024.05.25 |
|---|---|
| 백준 15486 - 퇴사 2 (C++) (0) | 2024.05.25 |
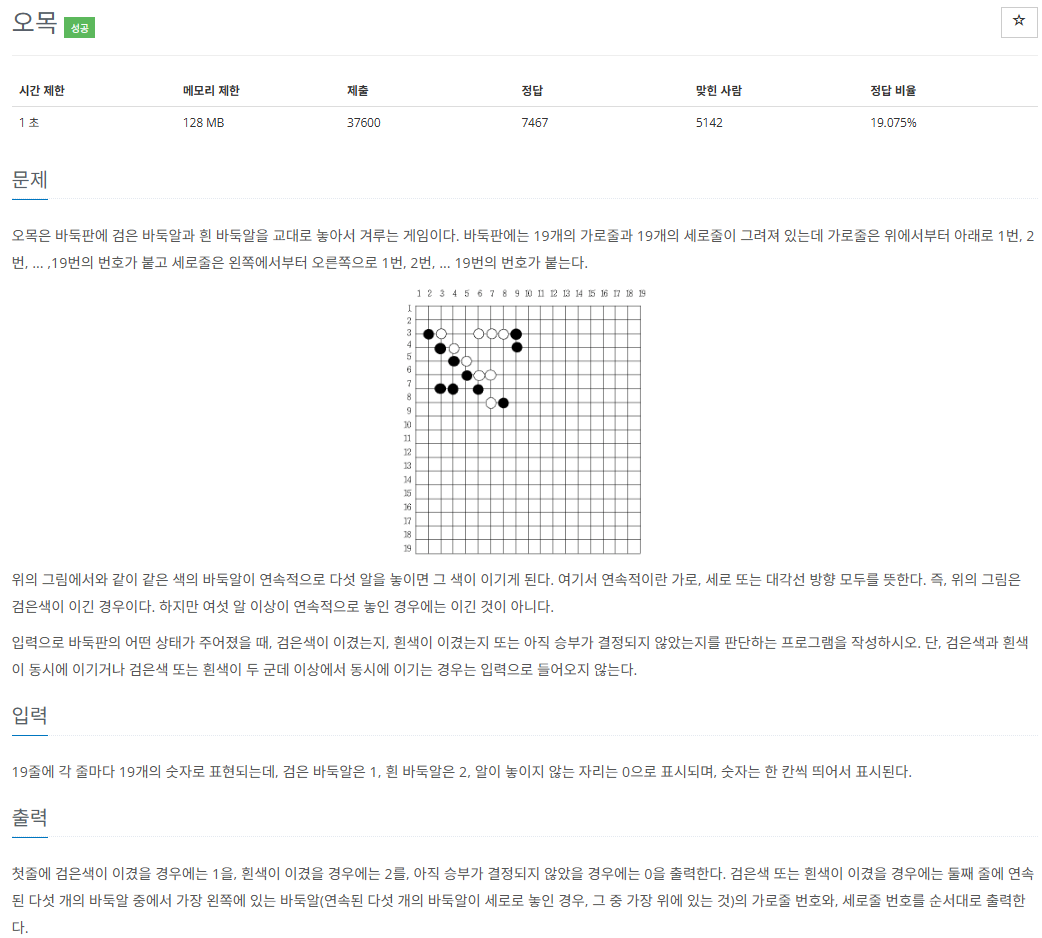
| 백준 2615 - 오목 (C++) (0) | 2024.05.22 |
| 백준 2436 - 공약수 (C++) (0) | 2024.05.21 |
| 백준 16678 - 모독 (C++) (0) | 2024.05.19 |