CPU는 컴퓨터를 구성하는 하드웨어중에서 가장 빠른 작업 처리 속도를 가지고 있다. 반면, 메인 메모리는 CPU에 비해 매우 낮은 작업 처리 속도를 가지고 있다.
두 하드웨어간의 속도 차이 때문에, CPU에서 메인 메모리에 직업 접근을 하게 되면 CPU에선 병목 현상이 발생하게 된다.
메인 메모리에 접근하여 데이터를 얻어오는 작은 작업의 시간이 CPU에선 수도 없이 많은 명령어를 처리할 수 있는 시간이기 때문이다.
이를 해결하기 위해 존재하는 것이 캐시메모리이다.
캐시 메모리
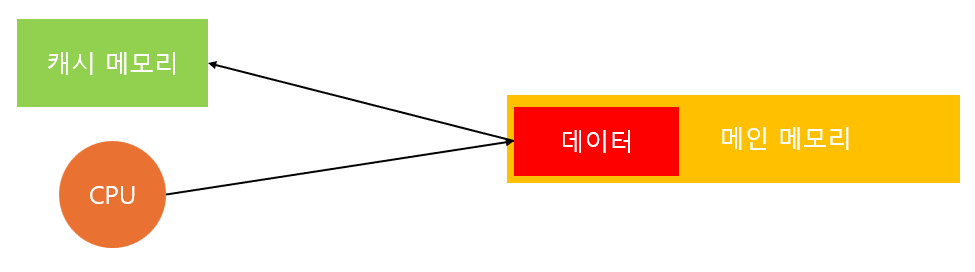
CPU는 필요한 데이터를 가져오기 위해서 메인 메모리에 접근을 할 수 밖에 없다. 하지만, 그 횟수를 최소화하기 위해 캐시 메모리를 사용하게 된다. CPU에서 메모리의 특정 주소에 접근하게 되면 그 주소를 시작으로 일정 크기만큼의 데이터를 한 번에 가져와 캐시 메모리에 저장하게 된다.
캐시 메모리는 메인 메모리에 비해 속력이 매우 빠르기 때문에, CPU에선 캐시 메모리에서 데이터를 탐색하는 것이 훨씬 효율적이기 때문이다.
하지만, 캐시 메모리는 메인 메모리에 비해 용량이 매우 작기 때문에 필요한 데이터가 캐시 메모리에 없을 경우 CPU는 다시 메인 메모리에 접근하여 캐시 메모리의 데이터를 새로 갱신하게 된다. 위에서 말했듯이, 메인 메모리에 접근하는 것은 성능상 손해가 크기 때문에 최소화하는 것이 좋다. 그렇다면, 캐시 메모리에 원하는 데이터가 최대한 많이 있을수록 메인 메모리에 접근하는 횟수가 적어질 것이며 성능의 손해를 최소화할 수 있을 것이다.
이 것을 캐시 적중률이라고 한다.
캐시 적중률

캐시 메모리에 현재 A,B,C,D,E,F 이렇게 6개의 데이터가 있다고 해보자.
CPU에서 A, B, C, X 이렇게 4개의 데이터를 필요로 한다면, A,B,C는 캐시 메모리에서 찾을 수 있지만, X의 경우엔 캐시 메모리에서 찾을 수가 없다.
이 경우, A,B,C 의 경우 캐시 적중이라고 표현하며, X에 대해선 캐시 미스(miss)라고 표현하게 된다.
캐시 적중이 얼마나 많이 발생하는가를 캐시 적중률이라고 표현하는 것이다.
그렇다면, 캐시 미스가 최대한 적게 발생해야 메인 메모리에 접근해서 캐시 메모리를 새로 채우는 과정이 적게 발생할 것이며 성능상 손해가 적게 될 것이다. 즉, 캐시 적중률이 높을수록 성능상 손해를 적게 보고 있다고 말할 수 있는 것이다.
그렇다면, 캐시 적중률을 높이기 위해선 어떻게 해야할까?
캐시 적중률을 높이는 법
방법은 간단하다. 관련된 데이터를 메모리에 연속적으로 위치하게 하면 된다. 캐시 메모리를 채우는 방식은 CPU가 메인 메모리에 접근한 주소를 시작으로 특정 크기만큼 연속적으로 가져오는 방식이기 때문이다.
예를 들어, 특정 자료구조의 원소를 순회한다고 해보자. 1번째 원소와 2번째 원소가 메모리 상에서 먼 위치에 있다면, 각 원소에 접근할 때마다 캐시를 새로 채워야 하는 상황이 발생할 수 있다. 반면, 모든 원소가 순차적으로 붙어있다면 자료구조의 원소가 캐시 메모리에 존재할 가능성이 매우 높아지며, 캐시 적중률을 최대로 높일 수 있는 것이다.
이 때문에 배열과 리스트의 성능 차이가 발생한다. 배열은 그 구조상 모든 데이터가 메모리에 연속적으로 위치하게 되지만, 리스트의 경우 모든 원소가 동적으로 할당되어 포인터로 연결되어 있기 때문에 메모리의 다양한 위치에 분산되어 있다. 그렇기 때문에, 동일한 시간 복잡도의 연산이라도 배열 기반의 자료구조가 포인터 기반의 자료구조보다 일반적으로 우수한 성능을 보이게 된다.
배열 뿐만이 아니라 메모리 풀링 또한 캐시 적중률을 높이는데 도움이 될 수 있다. 미리 메모리를 할당해놓고 필요한 만큼 가져다 쓰는 방식이기 때문에, 모든 데이터가 메모리 상에 연속적으로 위치하게 된다. 메모리 풀링은 캐시 적중률을 높일 뿐만 아니라 메모리 외부 단편화를 해결하는 데도 큰 도움이 되기 때문에 잘 활용하면 성능상 큰 이점을 얻을 수 있을 것이다.
'CS' 카테고리의 다른 글
| CS (Computer Science) - 가상 주소, 가상 메모리, 페이징, 세그멘테이션 (1) | 2024.05.18 |
|---|---|
| CS (Computer Science) - 내부 단편화, 외부 단편화 (0) | 2024.05.18 |
| CS (Computer Science) - 스레드 vs 프로세스 (1) | 2024.05.18 |
| CS (Computer Science) - Compare And Swap (CAS) (0) | 2024.05.18 |
| CS (Computer Science) - Memory Order (0) | 2024.05.17 |















