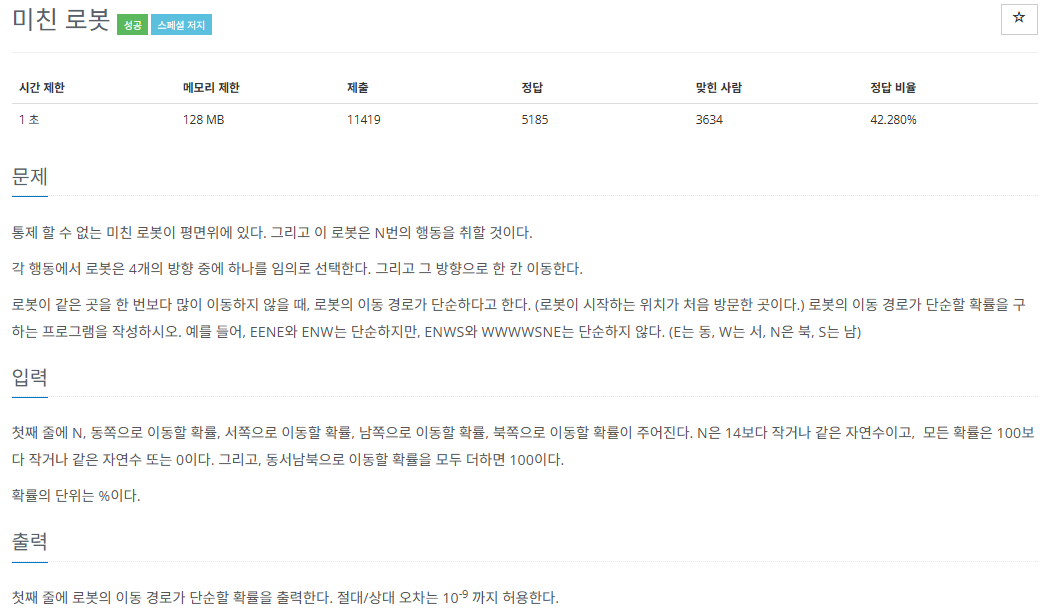
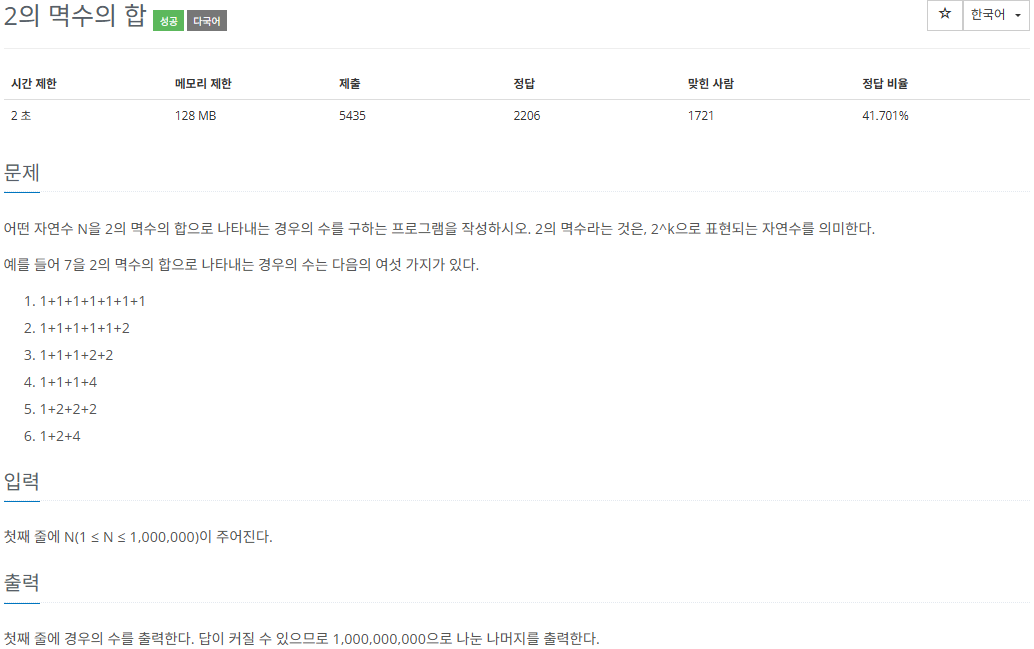
특정 마을에서 파티가 열린다고 했을 때, 모든 학생은 본인이 사는 마을에서 파티가 열리는 마을로 갔다가 다시 원래 마을로 돌아올 것이다.
이 때, 사는 마을 -> 파티 마을 -> 사는 마을의 경로를 통해 이동하게 될 것이다.
이 경로를 통해 이동할 때, 가장 큰 시간을 소비하는 학생의 소요 시간을 출력하면 된다.
모든 길은 단방향이기 때문에, 사는 마을 -> 파티 마을로 갈 때 소요되는 시간과 파티 마을 -> 사는 마을로 갈 때 소요되는 시간은 서로 다를 수 있다는 것을 주의해야 한다.
문제 풀이
먼저, 이 문제는 다익스트라를 이용하면 쉽게 해결할 수 있다.
사는 마을 -> 파티 마을로 가는 경로에 대해 다익스트라 알고리즘을 적용하여 최소 비용을 구하고,
파티 마을 -> 사는 마을로 가는 경로에 대해 다익스트라 알고리즘을 적용하여 최소 비용을 구할 수 있다.
두 경우의 비용을 더해서 각 학생의 소요 시간을 구할 수 있을 것이다.
다만, 입력으로 주어진 값을 평범하게 다익스트라 알고리즘을 적용하게 되면 시간초과가 발생할 수 있다.
왜냐하면, 1번 마을을 시작점으로 다익스트라 알고리즘을 수행해야 하고, 2번 마을을 시작점으로 다익스트라 알고리즘을 수행해야 하고, N번 마을까지 모두 다익스트라 알고리즘을 수행해야 한다.
파티 마을에서 원래 마을로 돌아올 떄엔 시작점이 파티 마을로 고정이므로 1번의 다익스트라로 해결할 수 있지만, 기존의 마을에서 파티 마을로 가는 경우에는 마을의 개수만큼 다익스트라 알고리즘을 수행해야 할 것이다.
하지만, 주어진 입력을 뒤집는다면 한 번의 다익스트라를 통해 답을 구할 수 있게 된다.
예를 들어, 5개의 마을이 있고 5번 마을에서 파티가 열린다고 해보자.
1번 마을 -> 5번 마을 : 비용 5
2번 마을 -> 5번 마을 : 비용 3
이렇게 입력이 주어진다면,
5번 마을 -> 1번 마을 : 비용 5
5번 마을 -> 2번 마을 : 비용 3
이렇게 마을의 시작점과 도착점을 뒤집어서 저장하는 것이다.
이 문제에선 특정 마을에서 파티 마을을 향해 가는 경로의 방향이 중요한 것이 아니라 비용이 중요한 것이므로 뒤집어서 파티 마을 -> 특정 마을로 해석해도 문제가 발생하지 않을 것이다.
그러므로, 입력을 그대로 저장한 뒤 파티 마을을 시작점으로 다익스트라 알고리즘을 1번 수행하고 입력을 반대로 저장한 뒤 파티 마을을 시작점으로 다익스트라 알고리즘을 1번 수행하게 되면 총 2번의 다익스트라 알고리즘으로 답을 구할 수 있게 되는 것이다.
코드 풀이
void Dijk(std::vector<int>& _Cost, std::vector<std::vector<std::pair<int, int>>>& _Link, int _StartNode)
{
std::priority_queue<std::pair<int, int>, std::vector<std::pair<int, int>>, std::greater<std::pair<int, int>>> Queue;
Queue.push({ 0, _StartNode });
while (Queue.size() > 0)
{
int CurNode = Queue.top().second;
int CurCost = Queue.top().first;
Queue.pop();
if (_Cost[CurNode] < CurCost)
{
continue;
}
for (int j = 0; j < _Link[CurNode].size(); j++)
{
int NextNode = _Link[CurNode][j].second;
int NextCost = _Link[CurNode][j].first;
int NextCostSum = CurCost + NextCost;
if (NextCostSum < _Cost[NextNode])
{
_Cost[NextNode] = NextCostSum;
Queue.push({ NextCostSum, NextNode });
}
}
}
}다익스트라 알고리즘 구현 코드이다. 우선 순위 큐를 활용하여 구현하였다.
int NumMan = 0;
int NumRoad = 0;
int PartyNode = 0;
std::cin >> NumMan >> NumRoad >> PartyNode;
std::vector<std::vector<std::pair<int, int>>> Link(NumMan);
std::vector<std::vector<std::pair<int, int>>> ReverseLink(NumMan);
for (int i = 0; i < NumRoad; i++)
{
int Start = 0;
int End = 0;
int Cost = 0;
std::cin >> Start >> End >> Cost;
Link[Start - 1].push_back({ Cost, End - 1});
ReverseLink[End - 1].push_back({ Cost, Start - 1 });
}위에서 말했던 것처럼 정방향으로 입력을 저장하고, 역방향으로도 입력을 저장해주었다.
std::vector<int> Costs(NumMan, INT_MAX);
std::vector<int> ReverseCosts(NumMan, INT_MAX);다익스트라를 사용해 갱신할 비용 배열도 정방향, 역방향 2개를 만들어주었다.
Dijk(Costs, Link, PartyNode - 1);
Dijk(ReverseCosts, ReverseLink, PartyNode - 1);정방향, 역방향으로 다익스트라를 1번씩 수행해 주었다.
int MaxCost = -1;
Costs[PartyNode - 1] = 0;
ReverseCosts[PartyNode - 1] = 0;
for (int i = 0; i < NumMan; i++)
{
int CurCost = Costs[i] + ReverseCosts[i];
MaxCost = std::max(MaxCost, CurCost);
}
std::cout << MaxCost;
return 0;정방향 비용은 파티 마을 -> 시작 마을의 비용이며 역방향 비용은 시작 마을 -> 파티 마을의 비용이다.
두 비용을 합한 값이 가장 큰 값을 구해주었고, 그 값을 출력해주었다.
여기서 중요한 것은 파티가 시작되는 마을의 값을 0으로 초기화해주어야 한다는 것이다.
다익스트라 알고리즘을 수행하게 되면, 파티 마을도 의도치 않게 비용이 갱신될 수 있으므로 반드시 제외해주어야 한다.

문제 풀이
#include <iostream>
#include <vector>
#include <queue>
#include <climits>
void Init()
{
std::ios::sync_with_stdio(false);
std::cin.tie(nullptr);
std::cout.tie(nullptr);
}
void Dijk(std::vector<int>& _Cost, std::vector<std::vector<std::pair<int, int>>>& _Link, int _StartNode)
{
std::priority_queue<std::pair<int, int>, std::vector<std::pair<int, int>>, std::greater<std::pair<int, int>>> Queue;
Queue.push({ 0, _StartNode });
while (Queue.size() > 0)
{
int CurNode = Queue.top().second;
int CurCost = Queue.top().first;
Queue.pop();
if (_Cost[CurNode] < CurCost)
{
continue;
}
for (int j = 0; j < _Link[CurNode].size(); j++)
{
int NextNode = _Link[CurNode][j].second;
int NextCost = _Link[CurNode][j].first;
int NextCostSum = CurCost + NextCost;
if (NextCostSum < _Cost[NextNode])
{
_Cost[NextNode] = NextCostSum;
Queue.push({ NextCostSum, NextNode });
}
}
}
}
int main()
{
Init();
int NumMan = 0;
int NumRoad = 0;
int PartyNode = 0;
std::cin >> NumMan >> NumRoad >> PartyNode;
std::vector<std::vector<std::pair<int, int>>> Link(NumMan);
std::vector<std::vector<std::pair<int, int>>> ReverseLink(NumMan);
for (int i = 0; i < NumRoad; i++)
{
int Start = 0;
int End = 0;
int Cost = 0;
std::cin >> Start >> End >> Cost;
Link[Start - 1].push_back({ Cost, End - 1});
ReverseLink[End - 1].push_back({ Cost, Start - 1 });
}
std::vector<int> Costs(NumMan, INT_MAX);
std::vector<int> ReverseCosts(NumMan, INT_MAX);
Dijk(Costs, Link, PartyNode - 1);
Dijk(ReverseCosts, ReverseLink, PartyNode - 1);
int MaxCost = -1;
Costs[PartyNode - 1] = 0;
ReverseCosts[PartyNode - 1] = 0;
for (int i = 0; i < NumMan; i++)
{
int CurCost = Costs[i] + ReverseCosts[i];
MaxCost = std::max(MaxCost, CurCost);
}
std::cout << MaxCost;
return 0;
}
'코딩테스트 문제 풀이 (C++)' 카테고리의 다른 글
| 백준 27172 - 수 나누기 게임 (C++) (0) | 2024.07.09 |
|---|---|
| 백준 1953 - 팀 배분 (C++) (0) | 2024.07.06 |
| 백준 7579 - 앱 (C++) (0) | 2024.06.25 |
| 코드 포스 (Code Forces) - Manhattan Circle (C++) (0) | 2024.06.21 |
| 코드 포스 (Code Forces) - Good Prefix (C++) (0) | 2024.06.20 |