
문제를 먼저 보자.
최대 일 수 N과 챕터의 수 M이 주어진다.
챕터의 정보는 {소요 일 수, 페이지 수} 쌍으로 주어지며, N일동안 최대 몇페이지를 읽을 수 있는가? 를 찾는 문제이다.
입력이 아래와 같이 주어진다면
7 7
3 10
5 20
1 10
1 20
2 15
4 40
2 200
4번째 챕터 (1, 20), 6번째 챕터 (4, 40), 7번째 챕터(2, 200)을 읽으면
7일간 260페이지를 읽을 수 있고, 이 것이 읽을 수 있는 최대 페이지 수 이다.
문제 풀이
이 문제는 전형적인 DP문제이다. DP문제 중에서도 가장 유명한 문제를 꼽으라면 피보나치 수열과 배낭 문제를 꼽을 수 있는데, 이 문제는 배낭 문제와 완전히 동일한 문제이다.
배낭 문제가 궁금하다면, 찾아보는 것도 좋을 것 같다. 하지만, 본 문제와 완전히 동일하기 때문에 이 문제를 이해한다면 배낭 문제도 이해할 수 있을 것이다.
7 7
3 10
5 20
1 10
1 20
2 15
8 60
2 200위의 입력을 기준으로 설명하도록 하겠다.
먼저, 표를 하나 그려보자.

가로는 최대 일 수를 의미하며, 세로는 챕터의 인덱스를 의미한다.
무슨 말인지 이해가 잘 안될 것이다.
자세히 설명하자면, 가로 인덱스가 1이라면 최대 일 수가 1이라고 가정을 한 상태에서 최대 페이지 수를 구한다는 것이다.
세로 인덱스는 1이라면, 1번 챕터까지 검사한 결과이고, 7이라면 7번 챕터까지 모두 검사한 결과라는 뜻이다.
(가로, 세로)가 (3, 5) 이라면 1~5번까지 챕터을 검사해서 최대 일 수가 3이라고 가정했을 때, 최대 페이지수가 몇인가? 를 구하는 것이다.
(가로, 세로)가 (6, 2) 이라면 1~2번까지 챕터을 검사해서 최대 일 수가 6이라고 가정했을 때, 최대 페이지수가 몇인가? 를 구하겠다는 것이다.
그렇다면, 이 표를 모두 갱신했을 때, (7, 7)이 결국 출력하고자 하는 답일 것이다.
최대 일 수인 7일동안 7개의 챕터를 모두 검사해서 최대 몇 페이지까지 읽을 수 있는가? 이게 (7, 7)의 값이기 때문이다.
일단, 표를 채우기 전에 논리적인 점화식을 세우고 가자.
먼저, 몇 가지 경우를 따져보자.
1. 현재 챕터를 읽을 수 없는 경우
현재 챕터를 읽을 수 있는 가, 없는 가에 대한 기준이 있을까?
만약, 최대 일수가 7일인데 한 챕터를 읽는데 8일이 걸린다면 그 챕터는 읽을 수가 없을 것이다.
이런 경우엔, 이 챕터를 포함하기 전의 최대값으로 갱신해주면 된다.
위의 입력을 보자. 6번 챕터는 읽는데 8일이 소요된다. 이런 경우 6번 챕터는 읽을 수 없기 때문에 0페이지를 읽는 것이나 마찬가지이다. 즉, 6번 챕터까지 검사한 최대 페이지 수는 5번챕터까지 검사한 최대 페이지 수와 동일할 것이다.
2. 현재 챕터를 읽을 수 있는 경우
현재 챕터의 소요 일 수가 최대 일 수보다 적어서 읽을 수 있다면, 이 경우에도 두가지 경우의 수로 나뉜다.
2 - 1. 해당 챕터를 읽지 않는 경우
2 - 2. 해당 챕터를 읽는 경우
만약, 해당 챕터를 읽지 않겠다면 챕터를 읽을 수 없는 경우와 마찬가지로 이전 챕터까지 읽었을 때의 최대 페이지 수를 그대로 가져오면 된다.
하지만, 만약 챕터를 읽겠다면?
(최대 일 수 - 소요 일 수)를 최대 일수로 가정한 상황에서 이전 챕터까지 검사한 최대 페이지 수 + 현재 챕터의 페이지 수가 될 것이다.
이게 무슨 말이냐!!
보자. 현재 7일을 최대 일 수로 가정하고 있다고 해보자.
여기서, 현재 챕터를 읽는데 4일이 소요된다고 한다면, 이 챕터를 읽고 남는 일 수는 3일이 된다.
즉 (이전 챕터까지 검사했을 때 3일간 읽을 수 있는 최대 페이지 수 + 현재 챕터의 페이지 수)가 해당 챕터를 읽었을 때의 최대 페이지 수가 될 것이다.
현재 챕터를 읽을 수 있는 경우에 최대 페이지 수는
std::max( 해당 챕터를 읽지 않는 경우의 페이지 수, 해당 챕터를 읽는 경우의 페이지 수) 가 되는 것이다.
아마 이해가 잘 안될 것이다. 표를 보며 다시 한 번 되새겨보자.
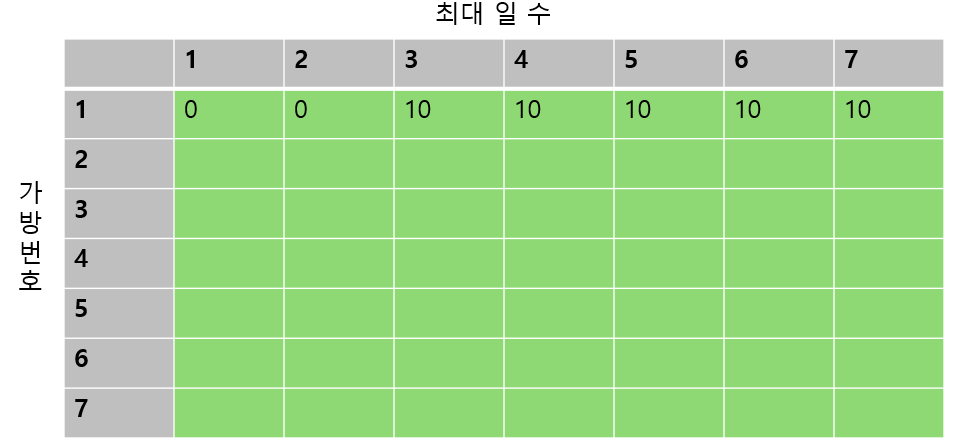
1번 가방까지에 대해서 표를 채워보면 이렇게 될 것이다.
최대 일수가 1일, 2일이라고 가정했을 땐, 1번 챕터를 읽을 수 없다.(소요 일수가 3일이기 때문에)
최대 일수가 3일 이상인 경우엔 1번 챕터 하나만 읽는 경우가 최대이기 때문에 10으로 모두 채워주면 된다.

이렇게 될 것이다.
먼저, 최대 일수가 1~4일 까진 2번 챕터를 읽을 수 없기 때문에 1번 챕터의 값을 그대로 가져오면 된다.
최대 일수가 5일이 될 때부턴 2번 챕터를 읽을 수 있다.
최대 일 수가 5일 일 때
-> std::max(2번 챕터를 안읽었을 때, 2번 챕터를 읽었을 때)가 표의 값에 들어갈 것이다.
2번 챕터를 안읽었을 때는 위칸의 값을 그대로 가져오면 되고,
2번 챕터를 읽었을 때는 1번 챕터까지 검사했을 때 0일동안 읽을 수 있는 최대 페이지 수 + 2번 챕터의 페이지 수이다.
위칸의 값은 10이고, 1번 챕터까지 검사했을 때 0일동안 읽을 수 있는 최대 페이지수 (0) + 2번 챕터의 페이지 수(20) 이므로 값은 20이 들어간다.
최대 일수가 6일 일 때
-> 2번 챕터를 안읽었을 때의 최대 페이지 수: 10
-> 2번 챕터를 읽었을 때의 최대 페이지 수 =
1번 챕터까지 검사했을 때 1일동안 읽을 수 있는 최대 페이지 수 + 2번 챕터의 페이지 수(20) : 20
최대 일수가 7일 일 때
-> 2번 챕터를 안읽었을 때의 최대 페이지 수: 10
-> 2번 챕터를 읽었을 때의 최대 페이지 수 =
1번 챕터까지 검사했을 때 2일동안 읽을 수 있는 최대 페이지 수 + 2번 챕터의 페이지 수(20) : 20
쭉쭉 채워보면,

이렇게 될 것이고, 답은 우측 하단의 245가 될 것이다.
풀이 코드
입력 및 초기화
int MaxDays = 0;
int NumOfChapter = 0;
std::cin >> MaxDays >> NumOfChapter;
std::vector<std::vector<int>> DP(NumOfChapter + 1, std::vector<int>(MaxDays + 1, 0));
std::vector<std::pair<int, int>>Chapters(NumOfChapter + 1);
for (int i = 1; i <= NumOfChapter; i++)
{
int Days = 0;
int Pages = 0;
std::cin >> Days >> Pages;
Chapters[i] = { Days, Pages };
}
먼저, 최대 일 수와 챕터의 수를 입력받은 후 배열을 선언하였다.
배열은 직관적으로 사용하기 위해 +1만큼의 크기로 resize하였다.
(+1을 하지 않으면, 1이 0번 인덱스이고 2가 1번인덱스이기 때문에..)
이후, 챕터 정보를 입력받아 배열에 저장하였다.
for (int i = 1; i <= NumOfChapter; i++)
{
for (int j = 1; j <= MaxDays; j++)
{
int CurDays = Chapters[i].first;
int CurPages = Chapters[i].second;
if (CurDays <= j)
{
DP[i][j] = std::max(DP[i - 1][j], DP[i - 1][j - CurDays] + CurPages);
}
else
{
DP[i][j] = DP[i - 1][j];
}
}
}
이후, 반복문을 돌며 검사하면 된다.
최대 일 수(j)를 기준으로 현재 챕터를 읽을 수 있다면, 읽지 않는 것과 읽는 것중 최대값으로 갱신하고
최대 일 수(j)를 기준으로 현재 챕터를 읽을 수 없다면, 이전 챕터까지 읽었을 때 최대 페이지 수를 그대로 가져오면 된다.
std::cout << DP[NumOfChapter][MaxDays];이후, 가장 마지막 원소를 출력해주면 된다.

'코딩테스트 문제 풀이 (C++)' 카테고리의 다른 글
| 백준 3896 - 소수 사이 수열 (C++) (0) | 2024.04.03 |
|---|---|
| 백준 2502 - 떡 먹는 호랑이 (C++) (0) | 2024.04.03 |
| 백준 1890 - 점프 (C++) (0) | 2024.04.02 |
| 프로그래머스 - 2 x n 타일링 (C++) (1) | 2024.04.01 |
| 프로그래머스 - 피로도 (C++) (0) | 2024.04.01 |


























