정규화라는 단어는 프로그래밍을 하다 보면 참 자주 듣는 용어이다.
어디에서 쓰이느냐에 따라 그 의미가 다소 달라진다.
이 게시글에선 데이터베이스에서 사용되는 정규화에 대해 알아보자.
정규화
데이터베이스의 정규화란, 하나의 테이블에서 중복된 데이터들을 최소화하는 것이다.
크게 설계된 하나의 테이블을 여러 테이블로 쪼개서 각 테이블에 중복된 데이터들이 최소로 존재하도록 하는 것이다.
왜 정규화를 해야할까?
데이터베이스의 설계가 잘못되어 있다면, 메모리의 낭비를 초래할 수도 있고 유지보수에 있어서 큰 걸림돌이 되는 등 다양한 문제가 발생할 수 있다. 이를 '이상 현상'이라고 하며, 이상현상은 세 종류가 존재한다.
이상현상
아래의 표를 보며, 세가지 이상 현상을 이해해보자.

1. 삽입 이상
삽입 이상이란, 데이터를 테이블에 추가하기 위해 의미 없는 데이터까지 추가해야 하는 상황을 의미한다.
위의 표와 같이 이름 - 나이 - 수업 - 교수 - 강의실 - 전화번호 구조로 이루어진 데이터 테이블이 있다고 해보자.
이 때, 신규 학생이 수업을 듣게 되면 데이터 테이블에 해당 학생의 데이터가 올라갈 것이다.
그런데, 해당 학생이 휴대폰을 잃어버려서 현재 전화번호가 없는 상황이라면?
전화번호 칸에는 Null을 삽입하여, 전화번호가 없다는 것을 표시해야 할 것이다.
만약, 학생의 전화번호를 기록하는 테이블이 별도로 있었다면?
위의 테이블의 전화번호 칸에 Null을 기록할 필요 없이, 학생이 새로 휴대폰을 개통하는 순간 전화번호 테이블에 정보를 삽입해 주면 된다.
2. 갱신 이상
만약, 김민수 학생이 실용음악에서 체육학으로 수업을 변경했다고 해보자. 그렇다면, 수업 항목에 저장된 실용음악을 체육학으로 변경하게 될 것이다. 하지만, 수업 항목에 저장된 데이터만 변경하게 되면 교수와 강의실 이름이 수업과 불일치하게 되는 문제가 발생한다. 즉, 올바르게 수정하려면 수업, 교수, 강의실을 모두 수정해야 하는 것이다.
또한, 이런 상황도 발생할 수 있을 것이다.
위의 테이블에는 노이만 학생에 대해서 두 개의 데이터가 존재하고 있다. 이 떄, 노이만 학생이 전화번호를 변경했다면?
3행에 있는 노이만 학생의 전화번호와 4행에 있는 노이만 학생의 전화번호를 모두 변경해야 한다.
만약, 노이만 학생의 데이터가 100개가 있다면 100개 모두 전화번호를 수정해야만 한다.
이처럼 데이터가 종속적으로 엮여있을 때, 엮여있는 모든 데이터를 수정해야만 하는 것은 정말 비효율적이라고 할 수 있다.
3. 삭제이상
해당 테이블의 데이터에는 학생의 개인정보와 학생의 수강정보를 함께 엮어서 저장하고 있다.
이 때, 체육학 수업이 폐지되었다고 해보자. 그렇다면, 데이터 베이스에 있는 체육학을 삭제해야 할 것이다.
위의 표에서 체육학을 삭제하려고 하면, 박성민 학생의 개인정보 데이터까지 삭제해야만 하는 상황이 발생할 것이다.
이처럼, 하나의 데이터를 삭제하기 위해 다른 데이터까지 함께 삭제해야만 하는 상황은 아주 잘못된 설계라고 할 수 있을 것이다.
제 1 정규화
위와 같은 이상현상이 발생하지 않도록 데이터 베이스를 설계하고자 하는 것이 정규화의 목적이다.
정규화는 여러 과정으로 이루어져 있다.
정규화 과정 중에서 제 1 정규화, 제 2 정규화, 제 3 정규화에 대해 알아볼 것이다.
제 1 정규화란, 테이블의 모든 컬럼(열)이 원자성을 충족하도록 하는 것이다.
원자성을 충족한다는 말은 무슨 뜻일까? 쉽게 말하면, 하나의 값만 가지고 있어야 한다는 뜻이다.

위의 테이블을 보면, 김민수 학생의 수업 정보에는 실용음악과 체육학이 둘 다 저장되어 있다.
이로 인해, 체육학 하나를 삭제하게 되면 김민수 학생의 실용음악 수강 정보도 함께 사라져버리는 삭제 이상이 발생하게 된다.

이렇게 데이터를 쪼개서 저장하게 되면, 삭제 이상을 방지할 수 있다. 이처럼, 테이블의 각 컬럼(열)이 하나의 값만 포함하도록 구성하는 것을 제 1 정규화라고 한다.
제 2 정규화
제 2 정규화란, 완전 함수 종속을 만족하는 테이블을 구성하는 것을 말한다.
완전 함수 종속이란, 기본키의 전체 집합이 아닌 부분집합에 대해 종속적인 컬럼이 없는 상태를 의미한다.
무슨 말인지 이해가 잘 안될 것이다.
표를 보며 이해해보자.

위의 테이블을 보자. 이 테이블의 기본키가 (이름 + 수강과목) 이라고 해보자.
특정 학생의 이름만 알고 있다고 했을 때, 데이터를 식별할 수 없다. (동명 이인의 존재 때문에)
하지만, 수강과목을 알게 되면 이름을 특정할 수 없어도 담당 교수는 확실하게 특정할 수 있게 된다.
즉, 담당 교수는 (이름 + 수강과목) 에 종속되지 않고 (수강과목)에만 종속되고 있다.
수강 과목만 알더라도, 담당 교수를 식별할 수 있다는 뜻이다.
이러한 경우, 수강 과목이 변경되었을 때 담당 교수까지 함께 변경하지 않으면 '갱신 이상'이 발생할 수 있다.
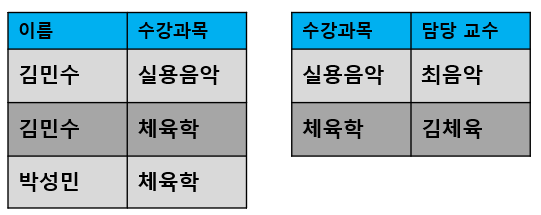
테이블을 이렇게 분리해보자.
이제, 특정 과목의 담당 교수 정보를 변경할 때 갱신 이상이 발생하지 않을 것이다.
(우측 테이블에서 특정 과목의 담당 교수 정보 1개만 갱신해도 되므로)
이처럼, 모든 데이터가 기본키의 전체집합에 대해서만 종속되도록 테이블을 분리하는 것을 제 2 정규화라고 한다.
제 3 정규화
제 3 정규화란, 제 2 정규화를 만족하는 테이블에서 이행적 종속을 없애는 것을 의미한다.
이행적 종속이 없는 상태란, 모든 컬럼이 기본키에 종속되면서 기본키를 제외한 어떠한 키에도 종속되지 않는 상태를 의미한다.

위의 테이블에서, 기본키는 (학번)이 된다.
학번은 학생별로 고유하게 부여되는 번호이므로 기본키의 역할을 할 수 있다.
학번만으로 이름, 소속학과, 학과장 정보까지 모두 결정할 수 있게 된다.
즉 이름, 소속학과, 학과장 정보는 학번에 대해 종속적이라고 할 수 있다.
하지만, 학과장 정보를 보자. 학과장은 학번에도 종속되지만 소속학과에도 종속되고 있다.
소속학과가 하나로 결정된다면, 해당 학과의 학과장 또한 하나로 결정된다.
즉, 학과장은 소속학과에 종속된다고 볼 수 있는 것이다.
이처럼, 기본키가 아닌 다른 키에 대해서도 종속되고 있는 상황을 이행적 종속이라고 하며 이를 제거하는 것이 제 3 정규화이다.

이렇게 분리하여 이행적 종속을 없애는 것이 제 3 정규화이다.
언뜻 보면, 제 2 정규화와 비슷한 부분이 많다.
다만, 제 2 정규화는 기본키의 부분 집합이 되는 특정 키에 대해 종속되는 데이터를 분리한 것이고
제 3 정규화는 기본키가 아닌 모든 키에 대해 종속되는 데이터를 분리한 것이다.
정규화의 장단점
데이터베이스를 정규화하게 되면, 위에서 말했던 것과 같이 이상현상의 가능성을 제거할 수 있으며 데이터의 안정성, 무결성을 보장할 수 있게 된다. 또한, 저장공간을 효율적으로 사용할 수 있게 된다.
하지만, 단점 또한 존재한다. 하나의 데이터 베이스를 여러 테이블로 쪼개면서 자연스럽게 join 연산의 횟수가 늘어나고 이로 인해 검색 속도가 느려질 수 있다는 것이다.
(join이란, 여러 테이블을 연결하여 하나의 테이블처럼 사용할 수 있도록 해주는 것)
이러한 문제점을 해결하기 위해, '반 정규화'라는 것을 사용하여 속도의 향상을 노려보기도 한다.
반 정규화에 대한 게시글도 추후 작성해보도록 하겠다.
'데이터베이스' 카테고리의 다른 글
| 데이터베이스 (DB) - 데이터의 무결성 (0) | 2024.06.05 |
|---|---|
| 데이터베이스 (DB) - 트랜잭션의 격리 수준 (0) | 2024.06.04 |
| 데이터베이스 (DB) - 트랜잭션과 ACID (1) | 2024.06.02 |
| 데이터베이스 (DB) - 키의 종류 (슈퍼키, 후보키, 기본키, 대체키, 외래키) (1) | 2024.05.31 |